AI integration in digital products: Leetio's proven approach

Why AI integration in digital products matters in 2025
In 2025, AI integration in digital products has become a standard part of product development. Static interfaces and generic user flows no longer meet user expectations. People interact daily with AI-powered systems across search, communication, and support, and expect similar responsiveness in every digital product they use. Companies now embed AI into onboarding, personalization, and decision logic, supported by large language models (LLMs), intelligent automation, and specialized AI tools. This adoption is shaping product strategies, influencing budget allocations, and redefining how digital products are deployed and improved over time.
Recent data shows:
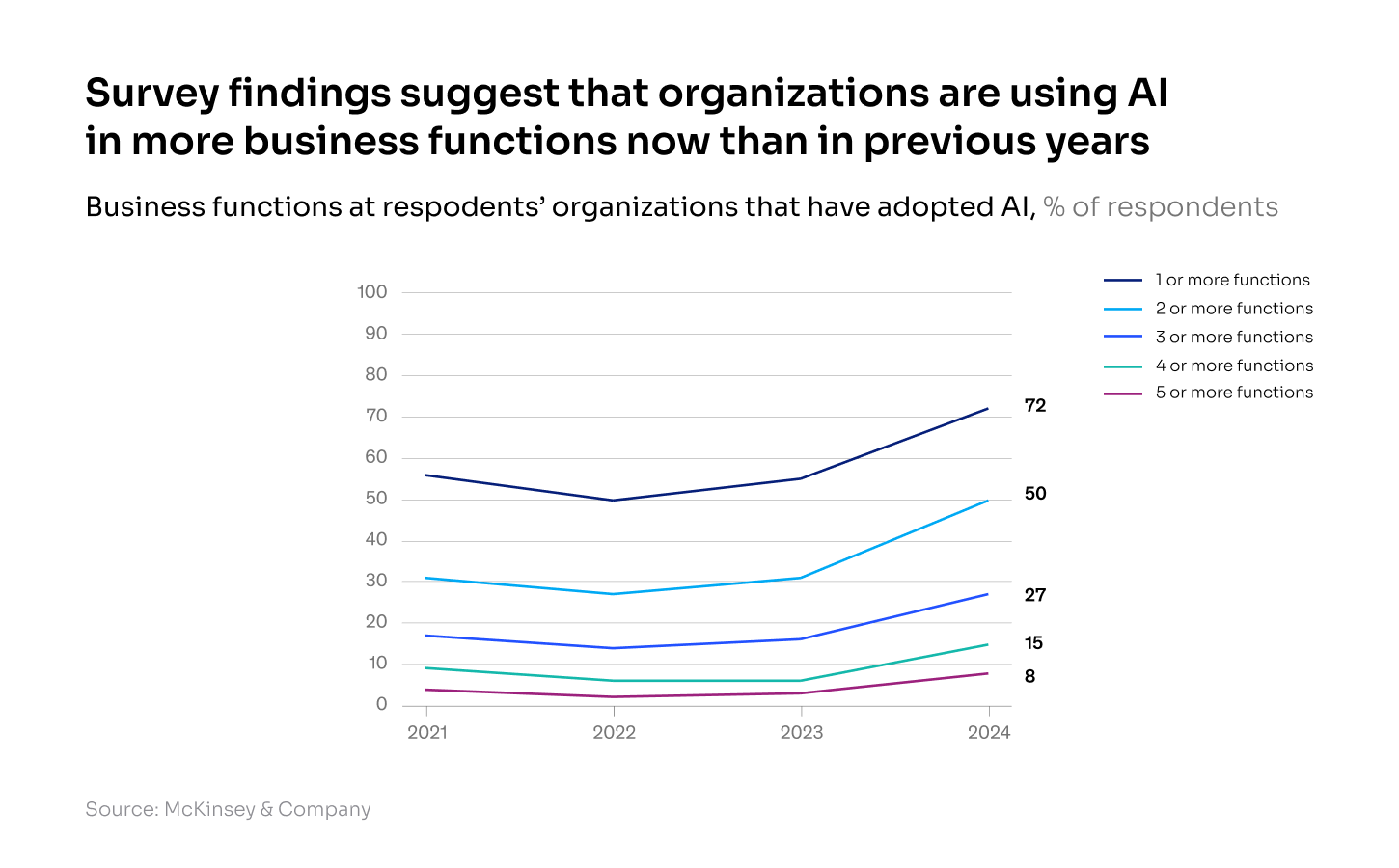
92% of C-suite executives expect to increase AI spending in the next three years, and more than half (+55%) plan to boost it by at least 10% (McKinsey).
OpenAI’s valuation and funding: With a $300 billion valuation in April 2025 following a $40 billion capital raise, it’s clear that significant investment is flowing into AI infrastructure (FutureSearch).
72% of organizations report regular use of generative AI in one or more functions — an increase from 65% earlier in the year (McKinsey).
At Leetio, AI is part of how we solve practical product challenges. We use it to reduce friction in onboarding, improve engagement, and extend the capabilities of static logic. Each AI implementation begins with a single question: What exactly needs to be improved, and is AI the right tool for the job? This focus helps us avoid overcomplicating things and ensures that AI works seamlessly as part of the product, not as an add-on.
AI in action: Use cases across industries
The role of AI in digital products depends on specific use cases. In most scenarios, the goal is to automate repetitive decisions, adapt to user behavior, or process data at scale. Below are examples of how various industries utilize AI in their production environments today.
These use cases are based on live implementations that utilize large language models, embeddings, vector search, and task-specific models, integrated either through APIs or custom pipelines.
AI in Fintech: Automation and personalization
AI focus: automation, personalization, decision support.
AI adoption in financial products is driven by the need to process large volumes of sensitive data in real time, meet complex regulatory requirements, reduce manual workload, and support accurate decision-making. It is used in tasks that require precision, control, and consistency. In most cases, AI is integrated into existing workflows to improve efficiency and expand capabilities without disrupting established systems.
Use Cases:
KYC and fraud detection: Automates document verification, detects irregular transaction patterns, and flags high-risk behavior.
Portfolio insights: Generates personalized investment summaries for users or advisors, extracts key market signals, and suggests asset rebalancing strategies based on individual profiles.
Compliance checks: Monitors communications and transactions to detect potential policy violations using named entity recognition, red-flag phrase detection, and hybrid NLP-rule systems.
AI copilots for analysts: Enables fast querying of earnings reports, filings, compliance documentation, and internal research using retrieval-augmented generation (RAG) built on machine learning models for embedding and classification.
 AI in Healthcare: Data extraction and personalization
AI in Healthcare: Data extraction and personalization
AI focus: data extraction, clinical decision support, personalization.
AI is increasingly utilized in healthcare to manage unstructured clinical data, facilitate clinical decision-making, and support patient-facing AI-powered applications, such as symptom triage and health coaching. Strict privacy regulations and the need for interpretability in high-risk contexts shape adoption. Most AI systems operate as assistive tools integrated into electronic health records (EHRs), triage flows, or wellness platforms.
Use Cases:
Clinical documentation summarization: Extracts key details from patient histories, consultation notes, and lab reports to reduce documentation workload and improve physician handover.
Patient intake and triage assistants: Automate data collection before appointments, categorize symptoms, and suggest possible care pathways based on structured prompts, symptom ontologies, and previous case logic.
Medical knowledge search: Enables clinicians to query internal protocols, drug interaction databases, and research papers using machine learning models for embeddings to power semantic retrieval.
Wellness personalization engines: Deliver personalized exercise, nutrition, or sleep plans based on self-reported data, wearable inputs, and behavioral patterns.
AI in EdTech: Adaptive learning and content generation
AI focus: adaptive learning, content generation, learning analytics.
AI in education personalizes content and assessments, supports instructors with content creation and tutoring tools, and offers feedback tailored to each student’s learning pace and style. Adoption is driven by the need to support diverse learners at scale, promote equitable outcomes, and maintain transparency to minimize bias in assessment and instruction. Most AI systems in EdTech are integrated into LMS platforms, authoring tools, or assessment systems.
Use Cases:
Adaptive learning engines: Adjust difficulty, format, or pace of content delivery based on learner performance, engagement metrics, and past responses.
AI content assistants for educators: Help generate quizzes, lesson plans, summaries, or multi-language content using curriculum-aligned models and structured knowledge bases.
Automated feedback and grading: Provides formative feedback on essays or code with NLP or code-analysis models, though final grading often includes manual review for open-ended responses.
Learning analytics and at-risk detection: Analyzes student behavior, engagement metrics, and completion rates to flag those needing intervention or support.
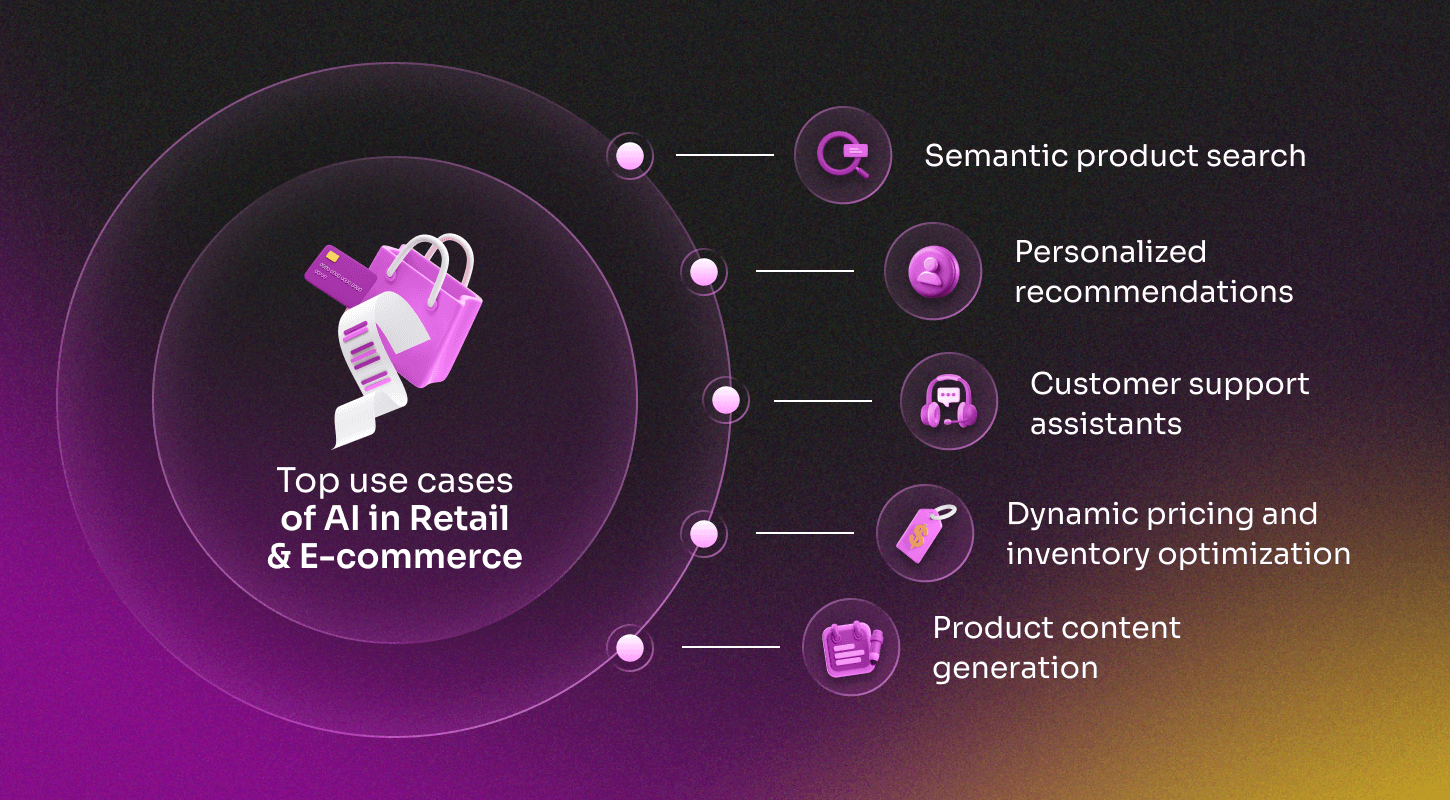
AI in Retail & E-commerce: Personalization and efficiency
AI focus: product discovery, personalization, operational efficiency.
AI in retail and e-commerce is utilized to enhance product discovery, minimize friction in the shopping experience, and facilitate backend operations such as pricing and inventory management. Integrations are typically focused on user behavior analysis, catalog enrichment, and service automation, embedded directly in storefronts or CRM systems. This demonstrates how AI-powered applications are reshaping customer journeys and operational workflows in commerce.
Use Cases:
Semantic product search: Interprets natural language queries to return relevant results, even when keywords don’t match exact product tags.
Personalized recommendations: Suggests items based on browsing history, previous purchases, and contextual signals such as seasonality or user intent.
Customer support assistants: Automates common queries related to orders, returns, and delivery, reducing the load on human agents and showcasing practical AI deployment.
Dynamic pricing and inventory optimization: Utilizes predictive models to adjust prices and restocking schedules in response to demand trends and sales velocity.
Product content generation: Automates the creation of product titles, descriptions, and metadata to improve SEO and reduce manual input.
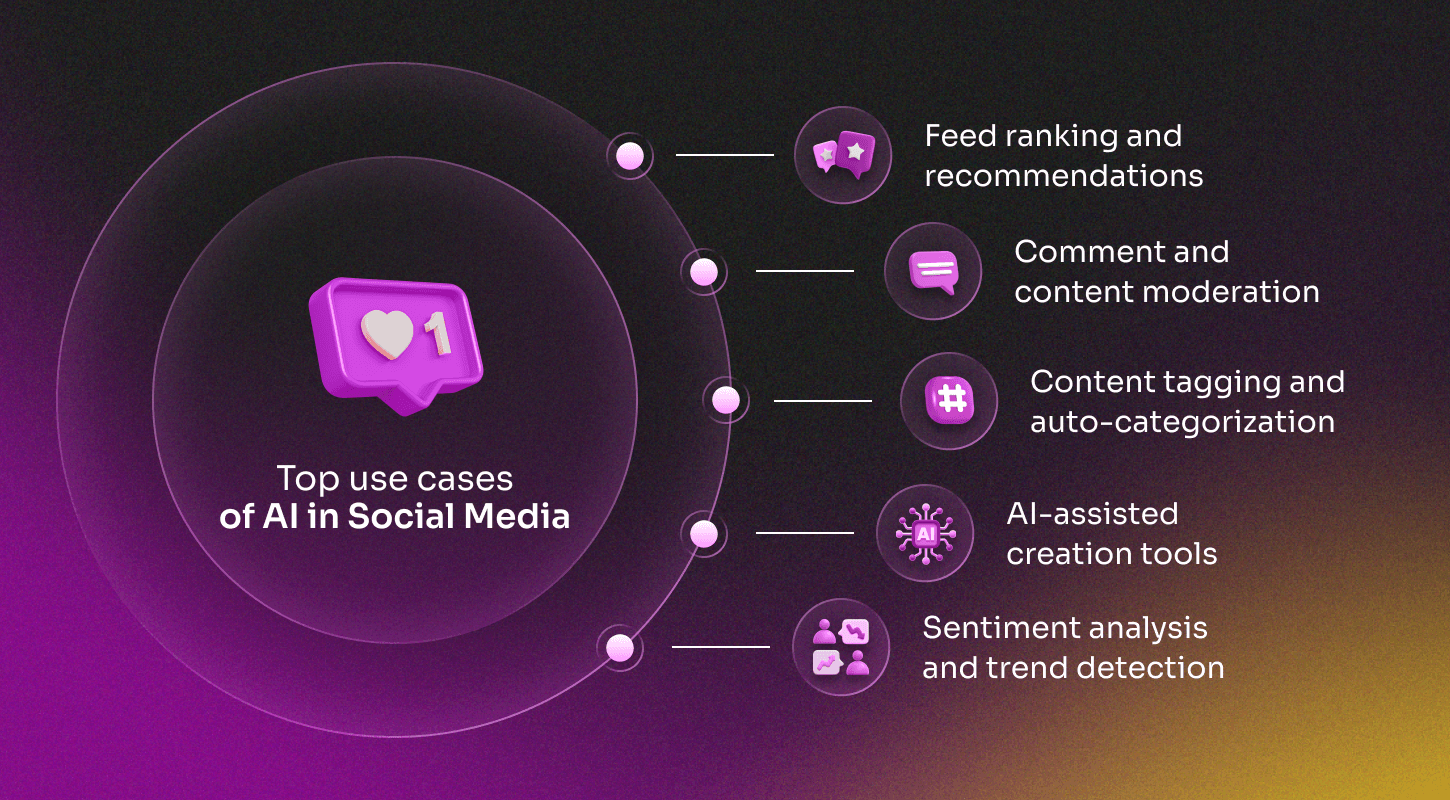
AI in Social Media: Content moderation and engagement
AI focus: content moderation, recommendation, and user engagement.
AI in social media platforms is used to filter and rank vast amounts of content in real time, personalize user experiences, and automate moderation. Most implementations operate at scale and rely on a mix of real-time inference and background analysis to support relevance, safety, and user retention. Social media represents one of the fastest-growing areas of AI adoption, where AI-powered applications influence how billions of people consume and engage with content online.”
Use Cases:
Feed ranking and recommendations: Prioritizes posts, stories, or videos based on predicted engagement, user interests, and social graphs.
Comment and content moderation: Flags hate speech, spam, or policy violations using classification models and hybrid rule systems.
Content tagging and auto-categorization: Automatically adds tags to images, videos, or text content to improve discoverability and relevance.
AI-assisted creation tools: Power features like image filters, auto-captions, hashtag suggestions, or voice-to-text in publishing flows.
Sentiment analysis and trend detection: Monitors public posts and comments to identify emerging topics, user sentiment shifts, or viral content.
AI-powered tools for seamless integration
Integrating AI into digital products involves combining models, frameworks, and infrastructure components to create a seamless and practical experience. Each serves a specific role: parsing data, generating content, ensuring performance visibility, or meeting regulatory requirements.
This section outlines widely used AI tools in 2025, grouped by function. It includes cloud APIs, open-source frameworks, and infrastructure systems that support document processing, model inference, monitoring, and secure deployment.
Large Language models (LLMs) for generative AI and reasoning
These models are the foundation for most generative and reasoning-based AI features. They process natural language and produce output in the form of summaries, answers, predictions, or recommendations.
Used for: content generation, summarization, chatbots, classification, data extraction, translation, ranking, and reasoning.
GPT‑4o (OpenAI): Multi-modal LLM with high performance across reasoning, summarization, and code. Used in both customer-facing chat interfaces and internal tools.
Claude (Anthropic): Prioritized for safety, interpretability, and low hallucination rates. Often used in regulated industries such as healthcare and finance.
Gemini (Google): Suited for document-heavy tasks, such as policy analysis, technical Q&A, or long-context understanding.
Mistral / Mixtral: Open-weight alternatives used in self-hosted environments for latency-sensitive or privacy-critical applications. A key advantage is their high degree of customization — allowing teams to fine-tune, adapt, and extend the models to meet specific product or compliance needs.
LangChain / LlamaIndex: Frameworks that coordinate prompts, memory, agent workflows, and LLM routing logic within applications. As part of modern AI tools, they enable scalable orchestration of generative AI features and support integration into production systems.

Document processing, OCR, and computer vision solutions
This category enables the extraction of text, entities, and tables from scanned documents, forms, images, or PDFs, transforming unstructured content into structured datasets.
Used for: onboarding forms, invoices, handwritten notes, healthcare records, and scanned checklists. These solutions are a common application of computer vision and often serve as a core component in digital products that require the extraction of structured data.
Google OCR (Vision API): A production-ready OCR engine with strong support for handwriting, multilingual text, and mobile photos. Used in SnapLog for recognizing patient information from surgical logs.
AWS Textract: Extracts not just text, but also the layout of tables, fields, and forms with confidence scores.
Tesseract: Open-source OCR, customizable but limited in accuracy for complex layouts or handwriting.
ABBYY FineReader / Kofax: Enterprise-grade OCR tools used in regulated document-heavy industries such as legal, insurance, and government.
docTR: A PyTorch-based open-source library for document image analysis, used in research, prototyping, and experimental AI implementation pipelines.

AI content and code generation platforms
These platforms form a major category of generative AI solutions, responsible for creating new content — such as marketing texts, support replies, lesson summaries, or software code — based on prompts, templates, or business logic.
Used for: onboarding assistants, course creation tools, SEO platforms, design mockups, and developer tools.
OpenAI DALL·E: Converts natural language prompts into generated images. Useful in feature illustrations, creative UI mockups, and media platforms.
Midjourney / SDXL: Focus on high-fidelity, artistic image generation. Widely used by designers and content creators.
Codex / StarCoder / Code Llama: Used to generate boilerplate code, write unit tests, or power AI-assisted developer environments.
Writer.com / Jasper: AI-powered writing tools adapted for corporate communications, documentation, or product descriptions.
Custom fine-tuned LLMs: Used where domain-specific tone, terminology, or output structure is required.

Retrieval-augmented generation (RAG) for context-aware AI
RAG combines language models with external data sources. The system retrieves relevant documents, forwards them to the model, and generates responses based on both the prompt and retrieved content. This setup supports grounded, context-aware outputs that reflect the underlying source material.
Used for: AI assistants, knowledge bases, customer support systems, and compliance dashboards
LangChain: Orchestrates RAG workflows — prompt templates, memory, tools, and logic for routing between functions.
LlamaIndex: Helps build knowledge graphs, structured indices, and document-based search interfaces.
Pinecone / Weaviate / Qdrant / Chroma: Vector databases used to store and search embeddings (dense representations of text or images) based on similarity.
OpenAI embeddings / Hugging Face sentence transformers: Used to convert text into embeddings that power search, clustering, or recommendations.

Monitoring, observability, and AI performance tracking
Monitoring tools provide visibility into how models behave in production, including how prompts perform, whether outputs degrade over time, and whether models drift away from expected behavior. These practices are critical for reliable AI deployment and long-term scalability.
Used for: product reliability, performance analysis, prompt tuning, version testing, and real-time alerts.
Arize / WhyLabs: Platforms for monitoring model quality, token usage, output distribution, and drift detection.
Weights & Biases / MLflow: Track experiments, model parameters, prompt changes, and evaluation benchmarks.
PromptLayer / LangFuse: Explicitly built for LLMs — track prompt versions, latency, feedback scores, and user sessions.
Grafana (custom setup): Used to visualize internal AI service metrics, such as retries, token costs, error rates, and fallback scenarios.

Privacy, compliance, and access control in AI projects
Critical in sectors such as fintech, healthcare, and edtech, this category ensures that user data is protected, AI decisions are traceable, and systems align with relevant regulations (e.g., GDPR, HIPAA, ISO 27001).
Used for: data masking, access control, logging, redaction, and audit compliance.
Private deployments (Ollama, Fireworks): Used to run LLMs locally or on private infrastructure to prevent data exposure.
Token and rate control (OpenAI API configs): Ensure that no single user or team exceeds quotas or sends sensitive data without limits.
Presidio / Faker: Libraries for redacting PII or generating synthetic test data.
Temporal / Kafka-based audit trails: Used for logging AI-related actions in critical systems for later review or investigation, supporting secure AI deployment

These tools form the technical foundation for modern AI products in 2025. While the specific stack varies depending on the project’s scope and industry, most implementations typically combine several key components: a language model, a retrieval system, a monitoring layer, and access controls. Selection depends on accuracy, latency, data sensitivity, and integration context.
Rather than relying on a single solution, production-grade AI requires assembling purpose-fit tools to ensure traceability, maintainability, and measurable value in real-world conditions.

Leetio’s process for building AI-driven products
At Leetio, AI is evaluated the same way as any other technology. In both new and existing products, we define the problem first and apply AI only when it offers a clear advantage.
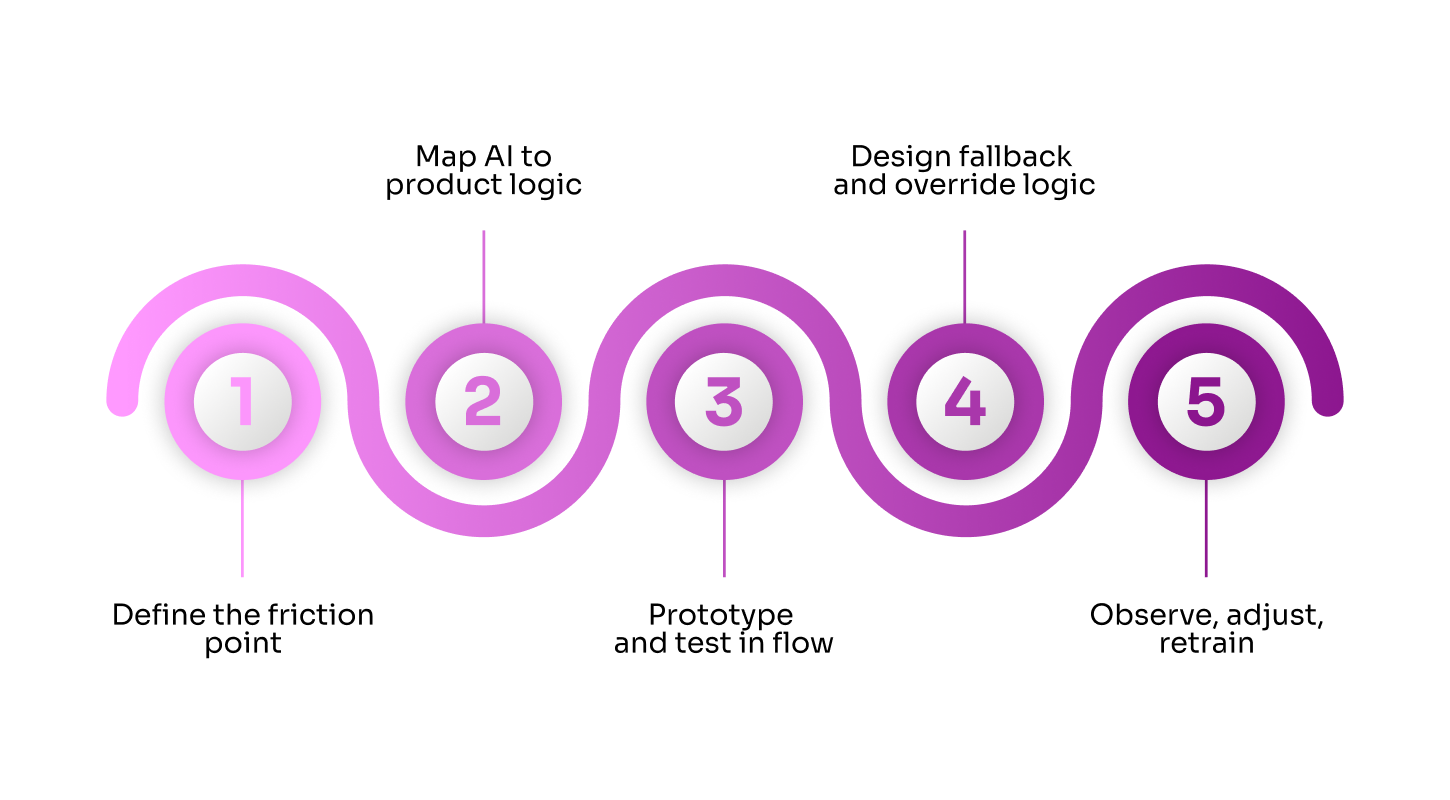
Our process for delivering production-ready AI features
Define the friction point: We begin by identifying exactly where users get stuck, drop off, or require additional guidance. AI is only considered when it solves a specific issue better than deterministic logic.
Map AI to product logic: We select the right type of model based on the task's requirements — generation, prediction, ranking, or classification. This might involve using off-the-shelf solutions like Qwen, Mistral, LLaMA, or Claude for language-based tasks, or combining them with embedding search and domain-specific classifiers where needed. Such choices are crucial for the reliable deployment of AI in production environments.
Prototype and test in flow: AI features are tested directly in the user flow (not in isolation) to evaluate output quality, latency, and UX implications.
Design fallback and override logic: Every AI decision is paired with a fallback: either a default state, a cached response, or a user-controlled override. This ensures stability even when models fail.
Observe, adjust, retrain: We monitor token usage, output quality, user interaction, and error rates. Based on real-world performance, we update prompts, adjust model selection, or apply fine-tuning. Given the rapid pace of AI development, this process is revisited regularly to incorporate newer tools, techniques, and benchmarks.
Technical perspective: LLMs, RAG, and deployment best practices
Prompt engineering pipelines: We utilize structured templates with slot injection, fallback values, and language conditioning (tone, persona, etc.) to ensure consistency. Prompts are versioned and tested as code.
Model selection: GPT-4o is used for general-purpose tasks (such as summarization, classification, and generation), while domain-specific tasks may utilize Claude, Gemini, Mistral, or open-source models, depending on the requirements for cost, latency, and control. Such careful alignment ensures reliable machine learning models' performance in production.
Retrieval-augmented generation (RAG): When outputs must reflect proprietary data (e.g., internal documents, catalogs, user data), we apply RAG pipelines with LangChain and a vector database (e.g., Pinecone, Qdrant).
Async and batch logic: For non-blocking flows (e.g., enrichment, summarization, clustering), AI runs in queues (BullMQ) with retry logic and usage metering.
Monitoring and observability: Token usage, model success rates, fallback activation, and feedback signals are logged and visualized for post-launch tuning.
Security and compliance: Sensitive inputs are masked, logs are anonymized, and calls to external APIs are gated with token limits and rate control. When required, we route calls through on-prem or private models.

Yuri Varshavsky
CTO of Leetio
"When a client approaches us with ‘we need AI,’ our first step is to ask: why, and where in the workflow? Not every challenge benefits from machine learning, and in many cases, deterministic logic solves the problem more effectively. We analyse the friction points, map them to the right tools, and only then decide if AI adds real value. This discipline prevents wasted effort and ensures the solution aligns with business goals."
This approach keeps AI predictable, testable, and aligned with product goals. Each integration is scoped around measurable outcomes such as reducing manual effort, improving decision speed, or enhancing the user experience without adding unnecessary complexity.
Case study: How our approach works on a real project
In this section, we demonstrate how our AI integration process was applied in a real product scenario.
The project is SnapLog — a mobile and web application developed to optimize the collection and utilization of clinical data. From the beginning, it was clear that AI could play a role, but the scope, value, and implementation needed to be carefully defined.
SnapLog operates in a context where speed, accuracy, and minimal interaction are essential. The challenge was to identify whether and where AI could improve the workflow without introducing unnecessary complexity, risk, or long-term maintenance overhead. We focused on applying AI in a specific area where it could provide measurable and consistent value, demonstrating a practical example of AI adoption.
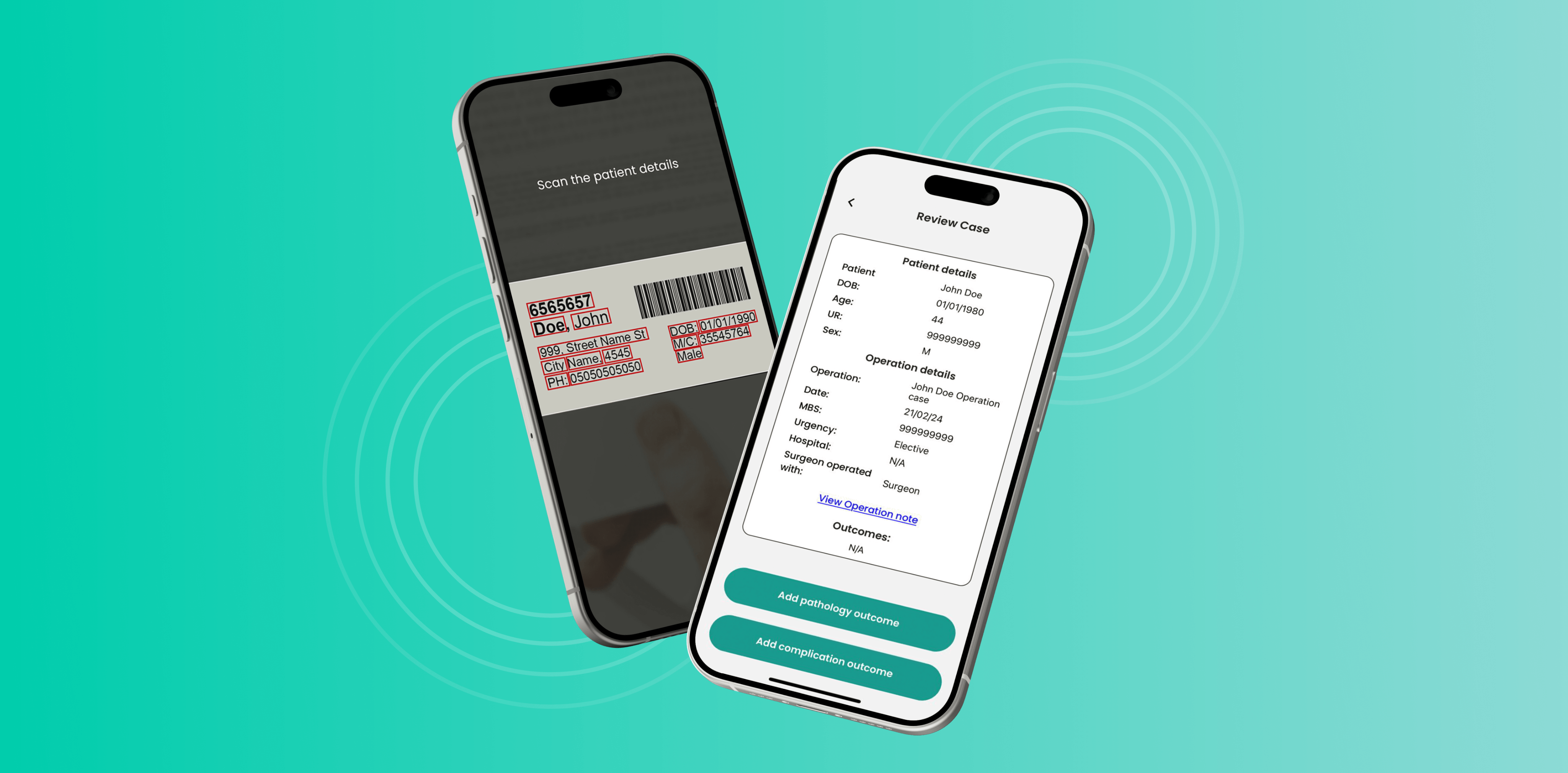
Each step of the process described earlier was applied in practice, and this section explains how we handled those stages in the context of this product.
Step 1: Defining the friction point in clinical workflows
The core friction was manual documentation. Surgeons were manually recording patient and procedure data, which slowed their workflow and increased the likelihood of errors. The process didn’t scale, especially in high-pressure environments like operating rooms.
We analyzed the entire workflow and identified one step that consistently required repetitive effort: transcribing structured clinical data from handwritten or printed labels. This task created a clear opportunity for automation. It was high-frequency, followed predictable patterns, and required no subjective judgment.
Step 2: Mapping AI to product logic and model selection
Once the target use case was defined, we evaluated the best way to automate it. The task involved extracting known fields—such as patient ID, surgery type, and timestamp—from visual input and converting them into structured data. Generative models were not relevant in this case.
We mapped this logic to a computer vision pipeline, starting with Google OCR for initial testing. Later in the process, we prepared for a switch to a custom-trained model based on real-case data to improve accuracy in low-light or handwritten scenarios.
The AI component was specifically designed to handle this task. It did not interfere with the rest of the workflow, which was managed through standard UI and API logic.

Step 3: Prototyping and in-flow testing for performance
We tested the AI pipeline directly within the data capture flow in the mobile app, under real usage conditions. This allowed us to evaluate model accuracy in real-world situations (lighting, camera angle, text quality) and measure total time from scan to result.
Performance benchmarks were defined before implementation. The AI pipeline had to return usable data in under three seconds on standard mobile hardware. Testing focused equally on speed, recognition accuracy, and how easily users could correct output when needed, highlighting practical aspects of AI deployment.
Step 4: Designing fallback and override logic for reliability
AI output was not always perfect. To avoid blocking the user or introducing risk, we implemented fallback behavior:
If confidence was low, the result was highlighted for manual review.
Users could always edit extracted fields before saving.
Data could be submitted without AI if needed.
This fallback logic ensured the app remained usable even when AI didn’t perform as expected. AI was utilized to expedite the workflow without making the system overly dependent on it, ensuring a stable AI-powered application in production.
Step 5: Observing, adjusting, and retraining AI for improvement
During testing and rollout, we monitored the frequency at which users edited or corrected AI-generated fields. This data revealed specific failure patterns, including text alignment issues, handwriting inconsistencies, and common field confusion.
These patterns informed the plan for Phase 2 of the AI pipeline:
Collect real-world labeled data
Fine-tune a domain-specific OCR model
Improve field segmentation and confidence estimation
Decisions were made based on real user behavior and data collected during the testing process.
The SnapLog project demonstrates how our AI integration approach works in practice: a narrow scope, high relevance, and a transparent fallback. AI was applied only where it directly reduced friction, and only after its value was proven within the actual workflow.
We applied AI as a technical solution to enhance data entry speed and accuracy while maintaining the stability and simplicity of the rest of the product.
Final Thoughts
AI in product development depends on clear problem definition, reliable infrastructure, and measurable outcomes. The AI implementation should integrate seamlessly into the existing system architecture and facilitate long-term maintenance.
Teams typically start by identifying a single point where automation or prediction can enhance speed, accuracy, or decision quality. Each integration must be tested in real usage conditions and monitored over time.
At Leetio, we design and build AI features that are ready for production. We focus on technical clarity, practical architecture, and business value, without unnecessary layers or shortcuts.
If you're planning a new AI feature or want to enhance its functionality in your product, we can help define the scope, select the appropriate tools, and implement it in a manner that suits your system and team. We work closely with product and engineering teams to ensure that every AI component supports clear goals and runs reliably in production.
Feel free to reach out to discuss your project, ask technical questions, or explore potential collaboration opportunities.
FAQ
- Common issues include poor data quality or format mismatches, latency when running large models in real-time, and architectural gaps (e.g., a lack of asynchronous pipelines or vector search). Teams also face challenges aligning AI output with product logic, managing non-deterministic behavior, and ensuring system reliability under load. These are frequent obstacles in AI implementation across industries.
- Success is typically tracked through task-specific metrics (e.g., accuracy, completion rate, latency), business KPIs (e.g., conversion, retention, cost reduction), and feedback loops from users or operations teams. Long-term value depends on consistency, maintainability, and measurable outcomes.
- Concerns include biased outputs, lack of transparency in decision-making, misuse of user data, over-reliance on automation, and challenges in auditability. These risks are particularly significant in sectors such as healthcare, education, and finance.
- Through retraining, fine-tuning, or prompt adjustment. Production-ready systems often include monitoring pipelines to detect model drift, shifting user intent, or feedback patterns, and then trigger model updates or routing logic accordingly. This approach applies to both large-scale LLMs and task-specific machine learning models.
- Start with a narrow use case that directly connects to a measurable product goal. Integrate AI into existing workflows where it can extend functionality, and design the implementation with clear observability, fallback logic, and performance monitoring.
- In most teams, a product manager defines scope and metrics, engineers handle integration and infrastructure, data scientists or ML engineers tune models, and QA or operations teams validate output quality and monitor ongoing performance.
CONTACT US

Sergii Kulikovskyi
Chief Executive Officer at Leetio
For detailed questions about products, their launch, or scaling.

Tanya Ivanishyna
Business Development Manager at Leetio
For questions about how our team can support you.
OUR OFFICE
Kaupmehe 7-120
10114 Tallinn
Estonia
C/ d'Aragó 562
Barcelona
Spain